GPU-accelerated hash cracker with Rust and CUDA
Introduction
In recent years, GPUs have become one of the most sought-after pieces of hardware in the world of computing. Originally designed for accelerating graphics-related computations, with applications such as video games, they now find applications in a wide variety of fields; most notably training AI models. The reason GPUs are so useful in such areas is that their design revolves around parallelism. Whereas regular CPUs are designed for performing sequential, I/O-bound work (e.g. get some input from the user, write it to a file, read the file, and send it to another user), GPUs can perform tens of thousands of operations concurrently, with these operations usually being more compute-oriented (e.g. float point operations). In this post, we’re going to use an NVIDIA GPU to write an accelerated MD5 hash cracker. We can leverage the GPU to compute thousands of hashes concurrently, making the process significantly faster than a CPU-based hash cracker. No prior knowledge of the internals of MD5 or the GPU is needed, though you should know what hash functions are, and what hash cracking is. This post is structured as follows:
Implementing MD5 in Rust on the CPU to understand the innerworkings of MD5
Understanding the basic architecture of the GPU, and implementing a classic example (vector addition) in CUDA
Integrating CUDA code with Rust code
Implementing MD5 on the GPU in CUDA, and writing a Rust frontend
Optimizations
Benchmarking The code for this post can be found here. Without further ado, let’s get started!
MD5
Before writing this post, I thought that MD5 would be very complicated, but implementing it, at least, is not that bad. MD5 is composed of 3 main parts: preprocessing the input, modifying the state based on the input, and finalizing the state into the digest.
The Internal State
As these steps suggest, the algorithm holds an internal state, composed of 4 registers (32-bit unsigned integers) labeled
AthroughD:
1
2
3
4
5
6
pub struct MD5 {
a: u32,
b: u32,
c: u32,
d: u32,
}
These registers are initialized to the constants A0 through D0, respectively:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
const A0: u32 = 0x67452301;
const B0: u32 = 0xefcdab89;
const C0: u32 = 0x98badcfe;
const D0: u32 = 0x10325476;
impl MD5 {
pub fn new() -> MD5 {
MD5 {
a: A0,
b: B0,
c: C0,
d: D0,
}
}
...
}
In the next section, we’ll implement the algorithm’s stages one by one.
Preprocessing
Given a message m of size k bits, we preprocess m as follows.
Append a single 0x80 byte to
mPad the resulting message with zeros until we get to a message with length 56 modulo 64
Append the 64-bit little-endian representation of
kFor example, if we have the message “hello”, after step 1 we’ll get the following message (the first 5 bytes are the ASCII representation of hello):
1
0x68 0x65 0x6c 0x6c 0x6f 0x80
The current message is of length 6, so we’ll pad it with 56 - 6 = 50 zeros to get to a message with size 56 = 64 - 8;
1
0x68 0x65 0x6c 0x6c 0x6f 0x80 0x00 X 50 times
Finally, the length of the original message is 5 bytes = 40 bits. The little-endian representation of this is 0x28 0x00 0x00 0x00 0x00 0x00 0x00 0x00, so the final message is:
1
0x68 0x65 0x6c 0x6c 0x6f 0x80 0x00 X 50 times 0x28 0x00 0x00 0x00 0x00 0x00 0x00 0x00
In Rust, we implement this as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
impl MD5 {
...
pub fn hash(&mut self, msg: &[u8]) -> Vec<u8> {
let mut pre_processed: Vec<u8> = msg.to_vec();
// Append a single 0x80 byte
pre_processed.push(0x80);
// Append 0x0 bytes until the message length is 56 mod 64
while pre_processed.len() % CHUNK_SIZE != CHUNK_SIZE - 8 {
pre_processed.push(0);
}
// Append the message length mod 2^64
(msg.len() * 8)
.to_le_bytes()
.iter()
.for_each(|x| pre_processed.push(*x));
...
}
}
Chunk Modification
Now for the core of the algorithm: modifying the state. Modifying the state is done in multiple iterations, each called a round. Each 64-byte chunk of the preprocessed message corresponds to one round. In each round, we first split the respective chunk into 16 32-bit words. We then perform 64 of the following operations:
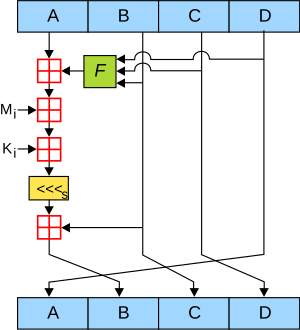
First of all, the registers B, C, and D, are used as input to a function F. This function changes based on the current iteration, and we’ll see exactly what it does shortly. The output of F, F(B, C, D), is added to the current value of register A. We then add two numbers to the resulting number: M_i and K_i. The first one, M_i, is one of the 32-bit words from the current chunk. More precisely, it is the g(i)-th word, where g is a function of i (the current iteration number) which we’ll define shortly. The second number, K_i, is a constant: it is defined as the integer part of the sine of i radians. In the implementation, we’ll store all of these values ahead of time in a constant table. After adding these numbers, we rotate the result (A + F(B, C, D) + M_i + K_i) left by S_i bytes, where S_i is a constant based on the current iteration number, also defined in a constant table. We finally add the value of B to the result, yielding the result leftrotate(A + F(B, C, D) + M_i + K_i, S_i) + B. Then, we modify the values of the registers as follows:
Agets assigned the current value ofDBgets assigned the value we computed (leftrotate(A + F(B, C, D) + M_i + K_i, S_i) + B)Cgets assigned the previous value ofB(before we modified B’s value)Dgets assigned the previous value ofC(before we modified C’s value) The functionsFandg, both of which are defined as piecewise functions based on the current iteration number, are defined as follows:
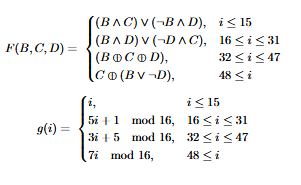
Now, let’s get to the implementation! First off, the constant tables:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
const SHIFT_AMTS: [u32; 64] = [
7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9,
14, 20, 5, 9, 14, 20, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 6, 10, 15,
21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21,
];
// Integer part of the sines of integers (as radians)
const K_TABLE: [u32; 64] = [
0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee, 0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be, 0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821,
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa, 0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed, 0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a,
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c, 0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05, 0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665,
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039, 0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1, 0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391,
];
We’ll also implement the leftrotate function:
1
2
3
fn leftrotate(x: u32, amt: u32) -> u32 {
(x << amt) | (x >> (32 - amt))
}
When processing the chunk, we first derive the 16 32-bit words:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
const CHUNK_SIZE: usize = 64;
const NUM_WORDS: usize = 16;
// Pre-processing...
// Process in successive 64-byte chunks
for chunk in pre_processed.chunks(CHUNK_SIZE) {
// Break into 16 32-bit words
let words: Vec<u32> = chunk
.chunks(CHUNK_SIZE / NUM_WORDS)
.map(|word| u32::from_le_bytes(word.try_into().unwrap()))
.collect();
// ...
}
The round operation, as you may recall, is performed 64 times:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// All values wrap around 2^32
const MODULUS: usize = 1 << 32;
...
let mut a = self.a;
let mut b = self.b;
let mut c = self.c;
let mut d = self.d;
for i in 0..CHUNK_SIZE {
let mut f;
let g;
if i <= 15 {
f = ((b & c) | ((!b) & d)) as usize % MODULUS;
g = i;
} else if 16 <= i && i <= 31 {
f = ((d & b) | ((!d) & c)) as usize % MODULUS;
g = (5 * i + 1) % 16;
} else if 32 <= i && i <= 47 {
f = (b ^ c ^ d) as usize % MODULUS;
g = (3 * i + 5) % 16;
} else {
f = (c ^ (b | (!d))) as usize % MODULUS;
g = (7 * i) % 16;
}
f = (f as usize + a as usize + K_TABLE[i] as usize + words[g] as usize)
% MODULUS;
a = d;
d = c;
c = b;
b = ((b as usize + leftrotate(f.try_into().unwrap(), SHIFT_AMTS[i]) as usize) % MODULUS) as u32;
}
The modulus is used so that the results will wrap around 2^32, instead of panicking as Rust normally does. After computing the new values of the registers, we add them to the current values, and reduce the result modulo 2^32:
for i in 0..CHUNK_SIZE {
// ... the round operations
}
self.a = ((self.a as usize + a as usize) % MODULUS) as u32;
self.b = ((self.b as usize + b as usize) % MODULUS) as u32;
self.c = ((self.c as usize + c as usize) % MODULUS) as u32;
self.d = ((self.d as usize + d as usize) % MODULUS) as u32;
Computing the Digest
After modifying the registers, we compute the final digest by concatenating the little-endian representations of the registers as follows: A || B || C || D where || denotes concatenation:
1
2
3
4
5
6
7
8
9
10
pub fn hash(&mut self, msg: &[u8]) -> Vec<u8> {
// ...
let mut digest = self.a.to_le_bytes().to_vec();
digest.append(&mut self.b.to_le_bytes().to_vec());
digest.append(&mut self.c.to_le_bytes().to_vec());
digest.append(&mut self.d.to_le_bytes().to_vec());
digest
}
We’re done with our first MD5 implementation! Let’s write some tests to make sure we did everything correctly:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#[cfg(test)]
mod tests {
use crate::md5::MD5;
#[test]
fn empty_msg_test() {
let mut hasher = MD5::new();
let msg = b"";
let digest = hasher.hash(msg);
let hexdigest = hex::encode(digest);
assert_eq!(hexdigest, "d41d8cd98f00b204e9800998ecf8427e");
}
#[test]
fn hello_msg_test() {
let mut hasher = MD5::new();
let msg = b"hello";
let digest = hasher.hash(msg);
let hexdigest = hex::encode(digest);
assert_eq!(hexdigest, "5d41402abc4b2a76b9719d911017c592");
}
}
Running the tests, we get:
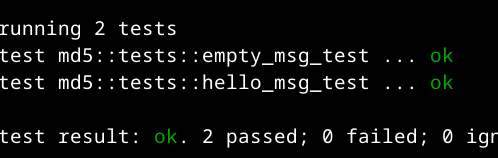
Awesome! In the next section, we’ll learn about the GPU, and what CUDA is.
GPU Programming 101
As mentioned at the start of this post, GPUs were originally intended for graphics applications, but now find their way into a lot of industry areas, due to their unparalleled parallelism (pun intended) capabilities. There are many languages used for such GPGPU (general-purpose GPU) programming, but for NVIDIA GPUs, which is what I own, the most common language is called CUDA (Compute Unified Device Architecture). Functions in CUDA can be classified into two major classes: host functions and device functions. Host functions are regular functions that run on the CPU; for example, the main function in a CUDA program has to be a host function. Device functions (also called kernels), on the other hand, run on the GPU. So how does running on the GPU help us? Host functions and device functions have two main differences:
Device functions have their own memory space, separate from the host memory (and so they can’t access host memory and vice versa)
Device functions run on multiple threads at once The second point is easier to see with an example; we’ll use the classic example of vector addition
Vector Addition in CUDA
Suppose you have two vectors, x and y, each containing N integers. If you were asked to write a function that adds those two vectors (i.e. output a new vector z defined as
z[i] = x[i] + y[i]) in a language like C, you might come up with something like the following function:
1
2
3
4
5
void add_vectors(int *x, int *y, int *z, int n) {
for (int i = 0; i < n; i++) {
z[i] = x[i] + y[i];
}
}
Once the vector sizes get large, though, this function will take a lot of time to run. This is due to the function being sequential: It first computes the first element of z, then the second one, then the third one, etc.
The Kernel
In CUDA, we can solve this problem differently. Instead of iterating over the two vectors, we can start a thread for each element in the resulting vector. In other words, each thread is responsible for computing one, and only one, element. All of the threads run in parallel, making the function much faster. We can implement such a kernel in CUDA as follows:
1
2
3
4
5
6
7
__global__ void vector_add(int *x, int *y, int *z, size_t n) {
int idx = threadIdx.x + blockDim.x * blockIdx.x;
if (idx < n) {
z[idx] = x[idx] + y[idx];
}
}
Some of the things here can be unfamiliar if you’ve never touched CUDA before. First off, the __global__ attribute means that this function is a global function: it can be called from both device functions and host functions. The blockDim, blockIdx, and threadIdx variables have to do with the thread’s position within the grid. When we call a CUDA kernel, we have to pass, in addition to the kernel’s arguments, two additional parameters: the block structure* and the block size. These parameters specify how the threads are organized with the grid of threads. The grid is split into blocks, and each of these blocks contain a certain number of threads. For example, if we have vectors of size N=1024, we might launch 32 blocks of threads, each containing 32 threads, resulting in a total of 1024 threads. The grid can also be split in a 2D and 3D manner, but throughout this post we treat the grid as 1 dimensional. Back to the kernel’s code:
blockDimis a variable containing the dimensions of the blocks within the grid. If we were to launch 128 blocks, each containing 32 threads,blockDim.xwould be 32blockIdxis a variable containing the index of the current thread’s block within the gridthreadIdxcontains the index of the current thread within its own block Using these variables, we can piece together the index of the current thread in the global grid: for example, if we are the 13th thread in the 37th block, and the blocks are of size 32, our global index in the grid is37 * 32 + 13 = 1197. Note that these variables are automatically defined inside the scope of a kernel. You might wonder why we’re checking whether the index of the thread is less than the size of the vectors. If the vectors we are adding were, for instance, of size 1023 instead of 1024, and we’d start 32 blocks of size 32 threads (the minimal number that can add two vectors of size 1023, sinceceil(1023 / 32) = 32), then the 1024-th vector would attempt to write to out-of-bounds memory, causing memory corruption issues. Therefore, we have to perform bounds-checking. Besides that, as mentioned earlier, each thread is responsible for a single element, eliminating the need for a sequential for-loop. Now that we’ve written the kernel, let’s write the host function, and see how to manage device memory and call the kernel.The Host Function
Like in C, the entry point of a CUDA program is the main function. We’ll begin by initializing two vectors of size 1024:
1
2
3
4
5
6
7
8
9
10
11
#define N (1024)
int main() {
int x[N];
int y[N];
for (int i = 0; i < N; i++) {
x[i] = i;
y[i] = N - i;
}
}
Now for the interesting part: invoking the kernel. First, recall that host functions and device functions have a separate memory space, and therefore can’t access each other’s memory spaces. To solve this problem, we’ll have to copy x and y to the device memory space. First, we’ll allocate device memory for the new vectors. This is done using the cudaMalloc function, which is similar to regular malloc, except it writes the address of the newly allocated memory to a parameter instead of returning it:
1
2
3
4
5
int *d_x;
int *d_y;
cudaMalloc(&d_x, N * sizeof(int));
cudaMalloc(&d_y, N * sizeof(int));
Two notes about the above code:
The prefix
d_stands for device, and is commonly added in CUDA code to distinguish variables allocated on the host memory and variables allocated on the device memory. Similarily, you might see the prefixh_, which stands for hostWhen calling
cudaMalloc, we pass inN * sizeof(int)as the size instead ofN, sincexandys are vectors ofints, andcudaMalloctakes in the amount of bytes that need to be allocated To copy the contents ofxandytod_xandd_y, respectively, we use thecudaMemcpyfunction:
1
2
cudaMemcpy(d_x, x, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N * sizeof(int), cudaMemcpyHostToDevice);
The first and second parameters are the destination and source, respectively. The third parameter is the size. The fourth parameter indicates the direction of the copy; in this case, we are copying from the host memory to device memory. Analogously, to copy data from the device to the host, we’d use the flag cudaMemcpyDeviceToHost. At this point, d_x and d_y contain the contents of x and y. One last thing we need to do before calling the kernel is allocate space for the result vector z:
1
2
3
int *d_z;
cudaMalloc(&d_z, N * sizeof(int));
Now, let’s invoke the kernel:
1
2
3
4
const int num_blocks = 32;
const int num_threads = 32;
vector_add<<<num_blocks, num_threads>>>(d_x, d_y, d_z, N);
The only thing here unique to CUDA is the parameters inside the triple brackets, which, as mentioned earlier, indicate the number of blocks and the number of threads inside each block. In this example, we’re using 32 blocks of size 32. Now, we should have the result of the vector addition inside d_z. We aren’t finished yet, though; recall that we can’t access d_z from outside the device memory! If so, we’ll have to do one final cudaMemcpy, this time from the device to the host:
1
2
3
int z[N];
cudaMemcpy(z, d_z, N * sizeof(int), cudaMemcpyDeviceToHost);
Awesome! We’ll also add some code to inspect the first few elements of z:
1
2
3
for (int i = 0; i < 5; i++) {
printf("z[%d] = %d\n", i, z[i]);
}
We can compile this program with NVIDIA’s CUDA compiler, called nvcc:
1
nvcc -o vector_add ./vector_add.cu
Running the executable, we can see that the vector addition was performed successfully:
1
2
3
4
5
z[0] = 1024
z[1] = 1024
z[2] = 1024
z[3] = 1024
z[4] = 1024
All of the results are the same (1024 = N), as we defined x[i] = i and y[i] = N - i. We’ve written our first CUDA program! In the next section, we’ll see how this program can be integrated with Rust using Rust’s FFI, allowing us to perform CUDA vector addition on Rust vectors.
Integrating with Rust
Build Process
After having some trouble with the Rust integration, I found a very helpful repo that shows how to call CUDA functions from Rust. We first need to add a build.rs that compiles all of the CUDA code to a shared library. We’ll do this using the cc package, so we’ll first need to cargo add cc --build. In the build.rs, we use the cc::Build structure to compile the CUDA files:
1
2
3
4
5
6
7
cc::Build::new()
.cuda(true)
.flag("-cudart=shared")
.flag("-gencode")
.flag("arch=compute_61,code=sm_61")
.file("src/gpu_code/vector_add.cu")
.compile("libvector_add.a");
First, we call the cuda function with true to tell cc that it needs to use a CUDA compiler. We then add the following flags:
cudart=sharedtellsnvccto dynamically link the resulting binary with the CUDA runtime, resulting in a smaller binary size--gencodeandarch=compute_61,code=sm_61tellnvccto generate code for a specific GPU architecture. Since the architecture changes from version to version, code that runs on one GPU will not necessarily run on another. In our case, the61corresponds to the Pascal architecture, which is my GPU’s architecture- The last two lines tell
nvccto take, as input, the filesrc/gpu_code/vector_add.cu, which is where the CUDA vector addition program we’ve just written is, and output the shared librarylibvector_add.aThe Architecture
Right now, our CUDA library contains two things:
A vector addition kernel that takes in three
int *s and the length of the vectors- A main function that calls this kernel We can’t directly call the kernel through the Rust FFI, so we’ll need to replace the
mainfunction with a wrapper that takes in the Rust vectors, performs the necessary memory allocations, and invokes the kernel. This, however, presents us with another problem: CUDA doesn’t know what a Rust vector is. To solve this new problem, we’ll introduce a new, intermediate typeFfiVector, that both Rust and CUDA can work with. To make working with this type easier, we’ll implement traits that allow converting back and forth between anFfiVectorand aVec<usize>.The Rust code
As promised, we’ll start with defining the
FfiVectorstruct:
1
2
3
4
5
#[repr(C)]
pub struct FfiVector {
data: *mut usize,
len: usize,
}
The struct holds two elements: a mutable raw pointer to a usize (the elements of the vector), and the length. The raw pointer has to be mutable, as we want the CUDA code to be able to modify it. We annotate the struct with repr(C) so that it will have a continuous representation in memory, like C structs. This is crucial for allowing integration. Now, we’ll implement From<FfiVector> for Vec<usize> and the other way around:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
impl From<FfiVector> for Vec<usize> {
fn from(value: FfiVector) -> Self {
let n = value.len;
let data = value.data;
unsafe {
let data_slice = slice::from_raw_parts(data, n);
data_slice.to_vec()
}
}
}
impl From<Vec<usize>> for FfiVector {
fn from(value: Vec<usize>) -> Self {
let len = value.len();
let data = value.as_ptr() as *mut usize;
std::mem::forget(value);
FfiVector { data, len }
}
}
In the first conversion, we use slice::from_raw_parts to extract the elements of the FfiVector as a slice, and then call to_vec to convert them to a vector. In the second conversion, we call as_ptr on the vector to get a *const usize, and then cast it to a *mut usize. We also call forget on the original value, since otherwise, at the end of the function, value will be dropped, leaving data a dangling pointer. With this new structure, we can now link our Rust binary with the vector addition wrapper (we’ll write it in the next section) from the CUDA shared library:
1
2
3
4
#[link(name = "vector_add", kind = "static")]
unsafe extern "C" {
unsafe fn vector_add_wrapper(x: &FfiVector, y: &FfiVector, z: &FfiVector);
}
The link annotation specified what the binary should be linked against, and how so (statically or dynamically). In this case, we statically link against the vector_add library. We have to wrap this with an unsafe block, since Rust assumes all foreign functions to be unsafe. The extern "C" specifies that the function is an external function that adheres to the C calling convention. In the main function, we can now perform CUDA vector addition as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
fn main() {
const N: usize = 1024;
let x: Vec<usize> = (0..N).collect();
let y: Vec<usize> = (0..N).map(|i| N - i).collect();
let z: Vec<usize> = Vec::with_capacity(N);
let x_ffi = FfiVector::from(x);
let y_ffi = FfiVector::from(y);
let z_ffi = FfiVector::from(z);
vector_add_wrapper(&x_ffi, &y_ffi, &z_ffi);
for (i, val) in Vec::<usize>::from(z_ffi).iter().enumerate().take(5) {
println!("z[{}] = {}", i, val);
}
}
In the next section, we’ll replace the CUDA main function with vector_add_wrapper, allowing us to indirectly call the kernel from the Rust code.
The CUDA code
We’ll start by defining the FfiVector struct in CUDA:
1
2
3
4
5
6
typedef long long int64_t;
struct FfiVector {
int64_t *data;
int len;
}
I made the data be an int64_t * since on my machine Rust usizes are 64 bits and C ints are 32 bits. As we saw from its Rust definition, the vector_add_wrapper function takes in three pointers to FfiVectors, and returns nothing. We’ll begin by allocating memory for the vectors on the device with cudaMalloc:
1
2
3
4
5
6
7
8
9
10
void vector_add_wrapper(FfiVector *x, FfiVector *y, FfiVector *z) {
int64_t *d_x;
int64_t *d_y;
int64_t *d_z;
size_t vec_size = x->len * sizeof(int64_t);
cudaMalloc(&d_x, vec_size);
cudaMalloc(&d_y, vec_size);
cudaMalloc(&d_z, vec_size);
}
Then, we’ll copy the contents of the FfiVectors to the newly allocated device vectors:
1
2
cudaMemcpy(d_x, x->data, vec_size, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y->data, vec_size, cudaMemcpyHostToDevice);
Note that the contents of z don’t need to be copied, since z is the result vector. Now for the interesting part: the kernel invocation. This time, invoking the kernel is a bit more complicated, since we don’t know the length of the vectors ahead of time. We’ll therefore fix the block size to a constant 32 threads, and set the number of blocks to ceil(vector length / 32):
1
2
3
4
const int num_threads = 32;
const int num_blocks = CEIL((float)x->len / (float)num_threads);
vector_add<<<num_blocks, num_threads>>>(d_x, d_y, d_z, x->len);
The CEIL macro implements the ceiling function; I asked ChatGPT to define it. Finally, we copy the result, which is now stored in d_z, to the contents of the z, and free all of the device vectors using cudaFree:
1
2
3
4
5
cudaMemcpy(z->data, d_z, vec_size, cudaMemcpyDeviceToHost);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
Finally, we wrap the wrapper we’ve just written with extern "C" to make it callable from Rust, as such:
1
2
3
4
5
extern "C" {
void vector_add_wrapper(FfiVector *x, FfiVector *y, FfiVector *z) {
...
}
}
Let’s try running our Rust program:
1
2
3
4
5
z[0] = 1024
z[1] = 1024
z[2] = 1024
z[3] = 1024
z[4] = 1024
Nice! We successfully called the CUDA vector addition function from Rust! In the next section, we’re finally going to write the hash cracker, starting by planning its architecture, and then implementing it.
Implementing the Hash Cracker
Architecture
Before implementing the hash cracker, we need to understand how a regular, CPU-based, sequential hash cracker works. Given a wordlist W and a target digest D:
Hash message
W_ifrom the wordlist, and compare the result withD. If we have a match, stop and returnW_iRinse and repeat If so, there are two avenues through which we can introduce parallelism:
Parallelize the hash computation itself
Compute multiple digests in parallel Implementing the first option would be very hard, as most hash functions are designed by applying complex operations iteratively. For example, in MD5, the output of each of the 64 round operations depend on the current values of the registers. We also can’t operate on multiple chunks of the same message at a time for the same reason. Besides, this wouldn’t really help our use case, since most passwords are short, resulting in only one pre-processed chunk. This leaves us with the second option: compute multiple digests in parallel. To do this, we’ll start by introducing a new FFI type
FfiVectorBatchedthat packs together multipleFfiVectors. We’ll then write a CUDA kernel that takes in a batch of messages, and in which each thread is responsible for computing the digest of a different message. Instead of writing a single kernel that does all the work, we’ll split it into 3 kernels, one for each stage of MD5, leaving us with the following kernels:
md5_batched_preprocess: each thread is responsible for preprocessing a different messagemd5_batched_compute: each thread is responsible for modifying a single state according to its assigned messagemd5_batched_finalize: each thread finalizes its state into a digestThe Rust Code
Now for the more technical details. We’ll start by changing
FfiVector’s definition to represent a vector of bytes instead ofusizes (the conversion implementations to and fromVec<u8>are very similar to the previous ones, so I won’t include them here):
1
2
3
4
5
6
#[repr(C)]
#[derive(Debug)]
pub struct FfiVector {
data: *mut u8,
len: usize,
}
We then define FfiVectorBatched as a struct containing a mutable pointer to an FfiVector and a length:
1
2
3
4
5
6
#[repr(C)]
#[derive(Debug)]
pub struct FfiVectorBatched {
data: *mut FfiVector,
len: usize,
}
With this new type, we’d like to be able to convert between a Vec<Vec<u8>> and FfiVectorBatched and vice versa. This is done with the following trait implementations. We first implement a conversion between a vector of FfiVectors to an FfiVectorBatched to make things simpler:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
impl From<Vec<FfiVector>> for FfiVectorBatched {
fn from(value: Vec<FfiVector>) -> Self {
let len = value.len();
let data = value.as_ptr() as *mut FfiVector;
std::mem::forget(value);
FfiVectorBatched { data, len }
}
}
impl From<Vec<Vec<u8>>> for FfiVectorBatched {
fn from(value: Vec<Vec<u8>>) -> Self {
let len = value.len();
let ffi_vecs: Vec<FfiVector> = value.into_iter().map(|x| FfiVector::from(x)).collect();
FfiVectorBatched::from(ffi_vecs)
}
}
impl From<FfiVectorBatched> for Vec<Vec<u8>> {
fn from(value: FfiVectorBatched) -> Self {
let n = value.len;
let data = value.data;
unsafe {
let data_slice = slice::from_raw_parts(data, n);
data_slice.into_iter().map(|x| slice::from_raw_parts(x.data, x.len).to_vec()).collect()
}
}
}
The main function is very short. it takes in the path to a wordlist and a target digest, reads all strings from the wordlist, and passes the result and the target digest to the crack function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
fn main() -> Result<(), io::Error> {
unsafe {
init();
}
let mut wordlist_file =
fs::File::open(env::args().nth(1).expect("Expected wordlist file name"))?;
let mut wordlist_data = String::new();
let digest = env::args().nth(2).expect("Expected hash");
wordlist_file.read_to_string(&mut wordlist_data)?;
let wordlist = wordlist_data.lines().collect();
if let Some(result) = crack(&digest, wordlist) {
println!("Hash cracked: md5({result}) = {digest}");
} else {
println!("Couldn't crack hash");
}
Ok(())
}
The crack function iterates over the wordlist in chunks of size BATCH_SIZE, where BATCH_SIZE is a tunable hyperparameter. It passes each chunk to the md5_batched_wrapper function (this is the CUDA wrapper for batched MD5 hashing we’ll write in the next section), and compares each of the resulting digests with the target one, returning if it finds a match:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// From the wordlist, find a string whose digest matches the input; if such a string does not exist, return None
fn crack(digest: &str, wordlist: Vec<&str>) -> Option<String> {
let dec_digest = hex::decode(digest).expect("Failed to decode digest");
for chunk in wordlist.chunks(BATCH_SIZE) {
let digests = FfiVectorBatched::from(vec![vec![]]);
let batch = FfiVectorBatched::from(chunk.into_iter().map(|x| x.as_bytes().to_vec()).collect::<Vec<Vec<u8>>>());
// Hash the batch
unsafe {
md5_batched_wrapper(&batch, &digests);
}
let digests_vec: Vec<Vec<u8>> = digests.into();
// Check if we have a match
for (i, x) in digests_vec.iter().enumerate() {
if x == &dec_digest {
return Some(chunk[i].to_string());
}
}
}
None
}
You might already notice a possible place for optimization (checking for a match is done sequentially). We’ll only deal with optimization later though: our goal for now is to get a minimal POC working. That’s it for the Rust frontend! In the next section, we’ll get into the core of this article, which is writing a batched MD5 function in CUDA.
The CUDA Code
First of all, we represent the current MD5 state with a structure, analogous to the MD5 structure in our Rust implementation:
1
2
3
4
5
6
struct md5_ctx {
uint32_t a;
uint32_t b;
uint32_t c;
uint32_t d;
};
We’ll start by writing the batched MD5 wrapper, and work our way down from there. The wrapper takes in a batch of input FfiVectors, for which the digest is to be computed, and a batch of output FfiVectors, which will contain the output digests:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#define DIGEST_SIZE (16)
#define BATCH_SIZE (4096)
struct FfiVector {
uint8_t *data;
size_t len;
};
struct FfiVectorBatch {
FfiVector *data;
size_t len;
};
void md5_batched_wrapper(FfiVectorBatch *msgs, FfiVectorBatch *outs) {
uint8_t *digests = new uint8_t[BATCH_SIZE * DIGEST_SIZE];
FfiVector *vec_digests = new FfiVector[BATCH_SIZE];
// Run the batched MD5
md5_complete_batched(msgs->data, digests);
// Convert output into an FfiVectorBatch
for (int i = 0; i < BATCH_SIZE; i++) {
vec_digests[i].data = digests + i * DIGEST_SIZE;
vec_digests[i].len = DIGEST_SIZE;
}
outs->data = vec_digests;
outs->len = BATCH_SIZE;
}
We define digests, the buffer into which the digests will be stored, as a buffer of size BATCH_SIZE * DIGEST_SIZE bytes. We could’ve also defined it as a 2D array of shape [BATCH_SIZE][DIGEST_SIZE], but doing it this way saves us a lot of allocations. Each finalizing thread will write to its designated 16 bytes (e.g. thread 0 writes its finalized digest to bytes 0-15, thread 1 writes to bytes 16-31, etc.). We then call md5_complete_batched, which is the function that actually computes the digests, and create a new array of FfiVectors, where each vector’s data is the corresponding digest (vector 0’s data points to the digest of the 0th message, etc.). Finally, we set outs’s data to point at this new array of FfiVectors, and set its length to BATCH_SIZE since it contains BATCH_SIZE FfiVectors. Most of the work happens in md5_complete_batched. This functions begins by allocating memory for the kernel invocations that follow. In particular, it stores the preprocessed messages, as well as the context for each MD5 computation, in a 2D array:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
void md5_complete_batched(FfiVector *msgs, uint8_t *h_digests) {
uint8_t *h_pre_processed_msgs[BATCH_SIZE];
size_t h_pre_processed_sizes[BATCH_SIZE];
size_t h_orig_sizes[BATCH_SIZE];
md5_ctx *h_ctxs[BATCH_SIZE];
// Allocate space for each of the pre-processed messages
for (int i = 0; i < BATCH_SIZE; i++) {
int pre_processed_size = CEIL((float)(msgs[i].len + 8 + 1) / (float)CHUNK_SIZE) * CHUNK_SIZE;
h_pre_processed_sizes[i] = pre_processed_size;
h_orig_sizes[i] = msgs[i].len;
// Allocate space for the pre-processed message, memzero it, and copy the original message
cudaMalloc((void**)&h_pre_processed_msgs[i], pre_processed_size);
cudaMemset(h_pre_processed_msgs[i], 0, pre_processed_size);
cudaMemcpy(h_pre_processed_msgs[i], msgs[i].data, msgs[i].len, cudaMemcpyHostToDevice);
// Allocate space for the MD5 contexts and copy the initial context there
cudaMalloc((void**)&h_ctxs[i], sizeof(md5_ctx));
cudaMemcpy(h_ctxs[i], &init_ctx, sizeof(md5_ctx), cudaMemcpyHostToDevice);
}
}
For each message in the batch, we store the message’s size after pre-processing and the message’s original size (we’ll see later why this is useful). We then allocate enough memory for the pre-processed message, zero the newly allocated memory, and copy the original message to the start of the chunk, as needed in the pre-processing stage. Finally, we allocate memory for the MD5 context for this message, and copy a global variable init_ctx there. The init_ctx variable is initialized in the function init, and contains the initial MD5 state. This is done so that we won’t need to do this manually every time we set up a new context.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
md5_ctx init_ctx;
#define A0 (0x67452301)
#define B0 (0xefcdab89)
#define C0 (0x98badcfe)
#define D0 (0x10325476)
void init() {
// Initialize the individual init_ctx
init_ctx.a = A0;
init_ctx.b = B0;
init_ctx.c = C0;
init_ctx.d = D0;
}
Next, we invoke the pre-processing kernel. This kernel receives the following parameters:
A pointer to the pre-processed messages (
pre_processed_msgs)The pre-processed size of each message (
pre_processed_sizes)The original size of each message (
orig_sizes). This is needed because the original size of the message (in bits) is appended to the pre-processed message Before calling the kernel, we need to (1) calculate the number of blocks and (2) copy the relevant parameters into device memory. Starting with (1), as in the vector addition example, we fix the size of each block to 32 threads, and set the number of blocks toceil(BATCH_SIZE / 32):
1
2
const int threads_per_block = 32;
const int blocks_per_grid = CEIL((float)BATCH_SIZE / (float)threads_per_block);
Regarding (2), we allocate the following device buffers, and copy the corresponding host variables into them:
1
2
3
4
5
6
7
8
9
10
11
// Copy the array of pointers to pre processed messages to the device
cudaMalloc(&d_pre_processed_msgs, sizeof(uint8_t *) * BATCH_SIZE);
cudaMalloc(&d_pre_processed_sizes, sizeof(size_t) * BATCH_SIZE);
cudaMalloc(&d_orig_sizes, sizeof(size_t) * BATCH_SIZE);
cudaMemcpy(d_pre_processed_msgs, h_pre_processed_msgs, sizeof(uint8_t *) * BATCH_SIZE, cudaMemcpyHostToDevice);
cudaMemcpy(d_pre_processed_sizes, h_pre_processed_sizes, sizeof(size_t) * BATCH_SIZE, cudaMemcpyHostToDevice);
cudaMemcpy(d_orig_sizes, h_orig_sizes, sizeof(size_t) * BATCH_SIZE, cudaMemcpyHostToDevice);
// Preprocess the messages
md5_preprocess_batched<<<blocks_per_grid, threads_per_block>>>(d_pre_processed_msgs, d_pre_processed_sizes, d_orig_sizes);
cudaDeviceSynchronize();
The call to cudaDeviceSynchronize after calling the kernel ensures that all threads have finished executing the kernel before execution continues to the rest of the function. This is necessary so that we won’t begin modifying the state with a message that hasn’t yet been pre-processed. In the next section, we write the pre-processing kernel itself.
Pre-processing Kernel
Each thread begins by calculating its global index within the grid, performing bounds-checking, and adding the 0x80 byte after the original message:
1
2
3
4
5
6
7
8
9
10
11
12
13
// Preprocess a batch of messages
__global__ void md5_preprocess_batched(uint8_t **pre_processed_msgs, size_t *pre_processed_sizes, size_t *orig_sizes) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < BATCH_SIZE) {
int n = orig_sizes[idx];
int size_in_bits = 8 * n;
int pre_processed_size = pre_processed_sizes[idx];
// Add 0x80 byte
pre_processed_msgs[idx][n] = 0x80;
}
}
After this, it writes the little-endian representation of size_in_bits to the last 8 bytes in the pre-processed message. No padding is necessary, since we’ve memzero’d the pre-processed message after allocating it.
1
2
3
4
5
// Adding the length
for (int i = pre_processed_size - 8; i < pre_processed_size; i++) {
int offset_from_end = i - (pre_processed_size - 8);
pre_processed_msgs[idx][(pre_processed_size - 8) + ((pre_processed_size - i) - 1)] = (size_in_bits >> ((7 - offset_from_end) * 8)) & 0xff;
}
We’re done with the pre-processing kernel! The next kernel is the one that modifies the MD5 states.
Modification Kernel
As arguments, the modification kernel needs to receive the following:
The MD5
ctxs(the contexts to be modified)The pre-processed messages
The pre-processed sizes, to avoid out-of-bounds memory access As we did when calling the last kernel, we allocate device memory for the parameters, copy the corresponding host variables, and then invoke the kernel:
1
2
3
4
5
6
cudaMalloc((void**)&d_ctxs, sizeof(md5_ctx *) * BATCH_SIZE);
cudaMemcpy(d_ctxs, h_ctxs, sizeof(md5_ctx *) * BATCH_SIZE, cudaMemcpyHostToDevice);
// Modify the states (the core of the MD5 computation)
md5_compute_batched<<<blocks_per_grid, threads_per_block>>>(d_ctxs, d_pre_processed_msgs, d_pre_processed_sizes);
cudaDeviceSynchronize();
Like in the last kernel, each thread starts by computing its global index and performing bounds-checking. This time, however, the thread proceeds to access the pre-processed message, and then iterates over the message’s chunks:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#define CHUNK_SIZE (64)
// Modifying the contexts; this is the meat of the MD5 computation
__global__ void md5_compute_batched(md5_ctx **ctxs, uint8_t **pre_processed_msgs, size_t *pre_processed_sizes) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < BATCH_SIZE) {
int pre_processed_size = pre_processed_sizes[idx];
uint8_t *pre_processed_msg = pre_processed_msgs[idx];
md5_ctx *ctx = ctxs[idx];
for (uint8_t *chunk = pre_processed_msg; chunk < pre_processed_msg + pre_processed_size; chunk += CHUNK_SIZE) {
...
}
}
}
The body of the for-loop follows the Rust code pretty closely. It first breaks up the chunk into words:
1
2
3
4
5
6
7
8
9
uint32_t words[CHUNK_SIZE / WORD_SIZE] = {0};
// Break up the current chunk into words
for (int word_idx = 0; word_idx < CHUNK_SIZE; word_idx += WORD_SIZE) {
words[word_idx / WORD_SIZE] = chunk[word_idx] +
(chunk[word_idx + 1] << 8) +
(chunk[word_idx + 2] << 16) +
(chunk[word_idx + 3] << 24);
}
And then performs the round operations, which, as you may recall, rely on constant tables. CUDA supports a special type of memory for such variables known as constant memory. Access to constant memory is cached and much faster, though its size is limited. We can declare variables in the constant memory using the __constant__ attribute:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
__constant__ uint32_t shift_amts[64] = {
7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21,
};
__constant__ uint32_t k_table[64] = {
0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821,
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a,
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665,
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391,
};
Now we can perform the 64 round operations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// Start round
uint32_t a = ctx->a;
uint32_t b = ctx->b;
uint32_t c = ctx->c;
uint32_t d = ctx->d;
for (int i = 0; i < CHUNK_SIZE; i++) {
uint32_t f;
uint32_t g;
if (i <= 15) {
f = ((b & c) | ((~b) & d));
g = i;
} else if (16 <= i && i <= 31) {
f = ((d & b) | ((~d) & c));
g = (5*i + 1) % 16;
} else if (32 <= i && i <= 47) {
f = (b ^ c ^ d) ;
g = (3*i + 5) % 16;
} else {
f = (c ^ (b | (~d))) ;
g = (7*i) % 16;
}
f = (f + a + k_table[i] + words[g]);
a = d;
d = c;
c = b;
b = (b + leftrotate(f, shift_amts[i]));
}
Finally, the new values of the registers are added to the original ones:
1
2
3
4
ctx->a = (ctx->a + a);
ctx->b = (ctx->b + b);
ctx->c = (ctx->c + c);
ctx->d = (ctx->d + d);
That’s it for the modification. Our next kernel, the last one, is going to finalize the states into digests.
Finalization Kernel
Before calling this kernel, we allocate space for the output digests on the device. As input, the kernel takes in the contexts and the output digests. After calling it, we copy the results into h_digests, which is the output parameter for md5_complete_batched:
1
2
3
4
5
6
7
uint8_t *d_digests;
cudaMalloc((void**)&d_digests, DIGEST_SIZE * BATCH_SIZE);
// Copy into output buffer
md5_finalize_batched<<<blocks_per_grid, threads_per_block>>>(d_ctxs, d_digests);
cudaMemcpy(h_digests, d_digests, DIGEST_SIZE * BATCH_SIZE, cudaMemcpyDeviceToHost);
The kernel itself is not very complicated; Like the previous kernels, it starts with bounds checking. Then, it copies the register values of its MD5 context to the corresponding index in the digests output buffer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
__global__ void md5_finalize_batched(md5_ctx **ctxs, uint8_t *digests) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < BATCH_SIZE) {
int start = idx * DIGEST_SIZE;
md5_ctx *ctx = ctxs[idx];
for (int i = 0; i < WORD_SIZE; i++) {
digests[start + i] = (ctx->a >> (8*i)) & 0xff;
digests[start + WORD_SIZE + i] = (ctx->b >> (8*i)) & 0xff;
digests[start + 2*WORD_SIZE + i] = (ctx->c >> (8*i)) & 0xff;
digests[start + 3*WORD_SIZE + i] = (ctx->d >> (8*i)) & 0xff;
}
}
}
Finally, in md5_complete_batched, we free all of the device memory:
1
2
3
4
5
6
7
8
9
10
// Free our memory
for (int i = 0; i < BATCH_SIZE; i++) {
cudaFree(h_pre_processed_msgs[i]);
cudaFree(h_ctxs[i]);
}
cudaFree(d_pre_processed_msgs);
cudaFree(d_pre_processed_sizes);
cudaFree(d_orig_sizes);
cudaFree(d_ctxs);
cudaFree(d_digests);
That’s it! We’ve finished the first version of our hash cracker.
Testing
To test the hash cracker, we’ll use the classic rockyou.txt wordlist. We’ll start with cracking the hash of password, which appears in the first 10 lines of rockyou. As expected, the cracker does this in less than a second:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
> .\cudacracker.exe .\rockyou.txt 5f4dcc3b5aa765d61d8327deb882cf99
Hash cracked: md5(password) = 5f4dcc3b5aa765d61d8327deb882cf99
> > Measure-Command { .\cudacracker.exe .\rockyou.txt 5f4dcc3b5aa765d61d8327deb882cf99 }
Days : 0
Hours : 0
Minutes : 0
Seconds : 0
Milliseconds : 723
Ticks : 7234996
TotalDays : 8.37383796296296E-06
TotalHours : 0.000200972111111111
TotalMinutes : 0.0120583266666667
TotalSeconds : 0.7234996
TotalMilliseconds : 723.4996
Next, let’s crack the hash of heartbreaker07, which is the 507433th password in the list:
1
2
3
4
5
6
7
8
9
10
11
12
13
> Measure-Command { .\cudacracker.exe .\rockyou.txt b24aefc835df9ff09ef4dddc4f817737 }
Days : 0
Hours : 0
Minutes : 0
Seconds : 56
Milliseconds : 582
Ticks : 565826750
TotalDays : 0.000654892071759259
TotalHours : 0.0157174097222222
TotalMinutes : 0.943044583333333
TotalSeconds : 56.582675
TotalMilliseconds : 56582.675
Hmmm… not very fast (56 seconds). In the next section, we’re going to optimize the code in an attempt to reduce the runtime.
Optimization
Read our code, we can find several places that massively decrease the performance:
After hashing a batch of passwords, we compare the resulting digests to the target digest sequentially, instead of in parallel
Instead of allocating a single buffer for all of the pre-processed messages, we allocate a new buffer for each pre-processed message (i.e.
h_pre_processed_msgsis auint8_t **and not auint8_t *). This is extremely bad, since it makes the amount ofcudaMallocs we call scale linearly with the batch sizeA similar thing goes for allocating a new buffer for each MD5 context instead of allocating a single buffer for all of them
1D Context Array
We’ll start with solving problem 3. Recall that currently, the contexts are allocated as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
void md5_complete_batched(FfiVector *msgs, uint8_t *h_digests) {
...
md5_ctx *h_ctxs[BATCH_SIZE];
// Allocate space for each of the pre-processed messages
for (int i = 0; i < BATCH_SIZE; i++) {
...
// Allocate space for the MD5 contexts and copy the initial context there
cudaMalloc((void**)&h_ctxs[i], sizeof(md5_ctx));
cudaMemcpy(h_ctxs[i], &init_ctx, sizeof(md5_ctx), cudaMemcpyHostToDevice);
}
...
}
Or, graphically:
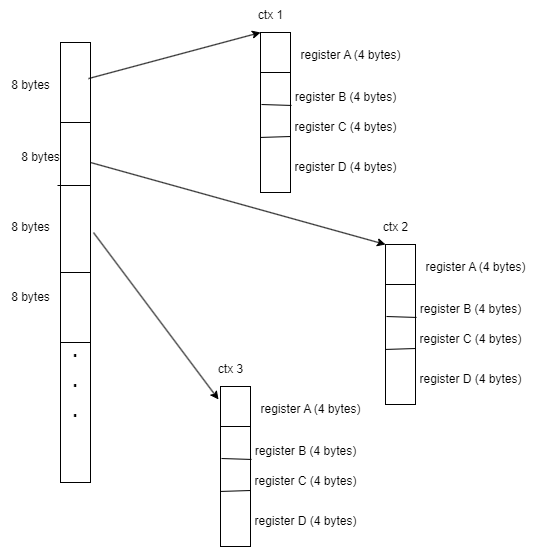
To avoid all of these unnecessary allocations, we can just remove the first layer of pointers, leaving us with only the contexts:

Remember the init function that initializes a global md5_ctx with the initial register values? To make implementing the above simpler, we’ll also add a global array of BATCH_SIZE contexts, each of which we’ll initialize with the initial register values:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// An array where each element is the initial context
md5_ctx init_ctxs[BATCH_SIZE];
void init() {
// Initialize the individual init_ctx
init_ctx.a = A0;
init_ctx.b = B0;
init_ctx.c = C0;
init_ctx.d = D0;
// Initialize the batched init_ctx
for (int i = 0; i < BATCH_SIZE; i++) {
init_ctxs[i].a = A0;
init_ctxs[i].b = B0;
init_ctxs[i].c = C0;
init_ctxs[i].d = D0;
}
}
Then, inside md5_complete_batched, we’ll allocate an array of BATCH_SIZE contexts on the device, and copy init_ctxs to it:
1
2
3
4
5
md5_ctx *h_ctxs[BATCH_SIZE * sizeof(md5_ctx)];
md5_ctx *d_ctxs;
cudaMalloc((void**)&d_ctxs, sizeof(md5_ctx) * BATCH_SIZE);
cudaMemcpy(d_ctxs, &init_ctxs, sizeof(md5_ctx) * BATCH_SIZE, cudaMemcpyHostToDevice);
We’ll also need to replace the kernels that use d_ctxs to take in an md5_ctx * instead of an md5_ctx **, and accommodate for this by replacing code of the form ctx->something with ctx.something, but this is pretty menial labor, so I won’t show it here. Let’s try cracking the same hash now and measuring the time:
1
2
3
4
5
6
7
8
9
10
11
12
13
> Measure-Command { .\cudacracker.exe .\rockyou.txt b24aefc835df9ff09ef4dddc4f817737 }
Days : 0
Hours : 0
Minutes : 0
Seconds : 39
Milliseconds : 51
Ticks : 390513421
TotalDays : 0.000451983126157407
TotalHours : 0.0108475950277778
TotalMinutes : 0.650855701666667
TotalSeconds : 39.0513421
TotalMilliseconds : 39051.3421
Nice! Compared with the previous 56 seconds, we got a 30% speedup! We can still do better, though.
1D Message Array
To fix point 2 (flattening the 2D preprocessed message array into a 1D array), we’ll need to do a bit more work. This is because, in contrast to the md5_ctx array, each element of the pre-processed message array has a different size. Therefore, we’ll have to find a way to index the 1D array from inside the kernels. As we did when optimizing the previous problem, it helps to think about this graphically. The preprocessed message array currently looks as follows:
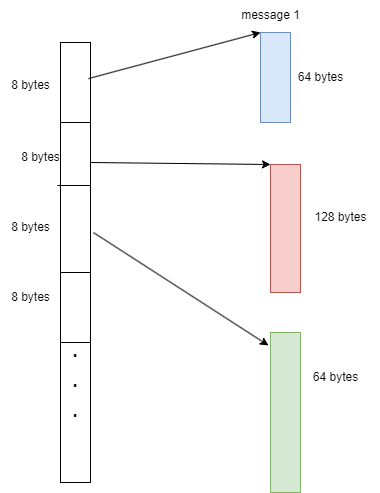
We’d like to change it so that it looks as such:
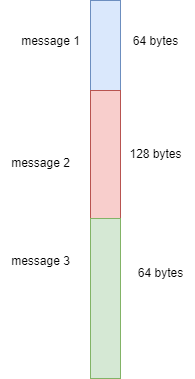
We can index into message i using the culminative sum of message sizes up until message i. In the above example:
The start of message 0 is index 0
The start of message 1 is
0 + the size of message 0 = 64The start of message 2 is
the index of message 1 + the size of message 1 = 64 + 128 = 192We can phrase this recurrently as follows:indices[i] = (i == 0 ? 0 : indices[i - 1] + sizes[i - 1]). Before we go ahead and write the code, there’s another point we need to think about: in the unoptimized code, we could’ve allocated the array of preprocessed messages ahead of time as such:
1
uint8_t *h_pre_processed_msgs[BATCH_SIZE];
Now, though, because we don’t know the total pre-processed size of all messages in the batch in advance, we’ll have to first calculate it, and only then allocate the array. While we’re doing that, we can also fill in the preprocessed size array and the original size array, as well as the culminative size array we defined recurrently above:
1
2
3
4
5
6
7
8
9
10
11
size_t h_culmn_sizes[BATCH_SIZE];
int total_size = 0;
// Calculate the total size of the messages after pre-processing
for (int i = 0; i < BATCH_SIZE; i++) {
int pre_processed_size = CEIL((float)(msgs[i].len + 8 + 1) / (float)CHUNK_SIZE) * CHUNK_SIZE;
h_pre_processed_sizes[i] = pre_processed_size;
h_orig_sizes[i] = msgs[i].len;
h_culmn_sizes[i] = (i == 0 ? 0 : h_culmn_sizes[i - 1] + pre_processed_size);
total_size += pre_processed_size;
}
We can now safely allocate the 1D pre-processed message array, and copy the original messages to their corresponding places:
1
2
3
4
5
6
7
8
uint8_t *h_pre_processed_msgs;
h_pre_processed_msgs = new uint8_t[total_size];
memset(h_pre_processed_msgs, 0, total_size);
for (int i = 0; i < BATCH_SIZE; i++) {
memcpy(h_pre_processed_msgs + h_culmn_sizes[i], msgs[i].data, msgs[i].len);
}
When calling the kernels that use pre_processed_msgs now, we have to pass in the culminative size array, so that the kernels will be able to perform indexing within pre_processed_msgs. Additionally, before invoking the kernels, we’ll need to copy h_culmn_sizes to device memory, and slightly change our existing memcpys, since we’re now dealing with 1D arrays:
1
2
3
4
5
6
7
8
uint8_t *d_pre_processed_msgs;
size_t *d_culmn_sizes;
cudaMalloc(&d_pre_processed_msgs, total_size);
cudaMalloc(&d_culmn_sizes, sizeof(size_t) * BATCH_SIZE);
cudaMemcpy(d_pre_processed_msgs, h_pre_processed_msgs, total_size, cudaMemcpyHostToDevice);
cudaMemcpy(d_culmn_sizes, h_culmn_sizes, sizeof(size_t) * BATCH_SIZE, cudaMemcpyHostToDevice);
Great! Obviously, we’ll have to perform some changes within the kernels to use the 1D indexing. This isn’t all that interesting, so I’ll only show how we change the pre-processing kernel:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// Preprocess a batch of messages
__global__ void md5_preprocess_batched(uint8_t **pre_processed_msgs, size_t *pre_processed_sizes, size_t *orig_sizes, size_t *culmn_sizes) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < BATCH_SIZE) {
int n = orig_sizes[idx];
int size_in_bits = 8 * n;
int pre_processed_size = pre_processed_sizes[idx];
// Add 0x80 byte
// Instead of 2D indexing (pre_processed_msgs[idx][n]), we index as such:
pre_processed_msgs[culmn_sizes[idx] + n] = 0x80;
// Adding the length
for (int i = pre_processed_size - 8; i < pre_processed_size; i++) {
int offset = i - (pre_processed_size - 8);
// 2D Indexing: pre_processed_msgs[idx][(pre_processed_size - 8) + ((pre_processed_size - i) - 1)]
pre_processed_msgs[culmn_sizes[idx] + (pre_processed_size - 8) + ((pre_processed_size - i) - 1)] = (size_in_bits >> ((7 - offset) * 8)) & 0xff;
}
}
}
Let’s see if we got a speedup!
1
2
3
4
5
6
7
8
9
10
11
12
13
Measure-Command { .\cudacracker.exe .\rockyou.txt b24aefc835df9ff09ef4dddc4f817737 }
Days : 0
Hours : 0
Minutes : 0
Seconds : 13
Milliseconds : 301
Ticks : 133010651
TotalDays : 0.000153947512731481
TotalHours : 0.00369474030555556
TotalMinutes : 0.221684418333333
TotalSeconds : 13.3010651
TotalMilliseconds : 13301.0651
Recall that our original runtime was 56 seconds, and after our last optimization it went down to 39 seconds. This is a 3x speedup! Additionally, the number of cudaMallocs now does not scale linearly with the batch size, so we can test the hash cracker with larger batch sizes (in the previous tests I set it to 512; batch sizes larger than that made my computer very slow). For example, if we set the batch size to 4096:
1
2
3
4
5
6
7
8
9
10
11
12
13
Measure-Command { .\cudacracker.exe .\rockyou.txt b24aefc835df9ff09ef4dddc4f817737 }
Days : 0
Hours : 0
Minutes : 0
Seconds : 7
Milliseconds : 50
Ticks : 70509114
TotalDays : 8.16077708333333E-05
TotalHours : 0.0019585865
TotalMinutes : 0.11751519
TotalSeconds : 7.0509114
TotalMilliseconds : 7050.9114
Our runtime is now 7 seconds, which is almost a 2x speedup! Let’s see if we can reduce it further, though.
Parallel Comparison
A short recap of our current hashing process:
Take N words from the wordlist
Pass them to the CUDA wrapper, and compute each of their digests
Sequentially compare each of the resulting digests with the target digest
Repeat until a match is found We’d like to remove step 3, and instead perform it during step 2. Besides removing the need for sequential comparison, this change also eliminates the need to finalize the contexts into digests. Recall that the finalization process consists of taking each of the little-endian representations of the registers, and concatenating them. Instead of doing this, we can convert the target digest into its corresponding context beforehand, and compare it with the finalized context. We’ll start with making a new wrapper:
md5_target_batched_wrapper. This wrapper takes in a batch of messages and a target digest (anFfiVector; this is the digest fed into the hash cracker). It converts the target digest into its corresponding context, and calls another function,md5_target_batched:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int md5_target_batched_wrapper(FfiVectorBatch *msgs, FfiVector *target) {
md5_ctx *target_ctx = new md5_ctx;
uint8_t *data = target->data;
// Fill target context registers with the target digest's ones
target_ctx->a = data[0] +
(data[1] << 8) +
(data[2] << 16) +
(data[3] << 24);
target_ctx->b = data[4] +
(data[5] << 8) +
(data[6] << 16) +
(data[7] << 24);
target_ctx->c = data[8] +
(data[9] << 8) +
(data[10] << 16) +
(data[11] << 24);
target_ctx->d = data[12] +
(data[13] << 8) +
(data[14] << 16) +
(data[15] << 24);
return md5_target_batched(msgs->data, target_ctx);
}
The inner function, md5_target_batched, is, for the most part, identical to md5_complete_batched (the function that computes batched MD5 hashes), except for its end. Instead of calling md5_finalize_batched, it calls md5_compare_ctx_batched:
1
2
3
4
5
6
7
8
9
int md5_target_batched(FfiVector *msgs, md5_ctx *h_target_ctx) {
md5_ctx *d_target_ctx;
cudaMalloc(&d_target_ctx, sizeof(md5_ctx));
cudaMemcpy(d_target_ctx, h_target_ctx, sizeof(md5_ctx), cudaMemcpyHostToDevice);
...
md5_compare_ctx_batched<<<blocks_per_grid, threads_per_block>>>(d_ctxs, d_target_ctx, d_match_idx);
}
This new kernel takes in the contexts computed by md5_compute_batched, the target context computed in md5_target_batched_wrapper, and a pointer to an integer called d_match_idx. In case one of the threads finds a match between its own context and the target context, it writes its grid index to d_match_idx. The function md5_compare_ctx_batched returns this index. The index is initialized to -1 (i.e. no match was found):
1
2
3
4
5
int *d_match_idx;
int h_match_idx = -1;
cudaMalloc(&d_match_idx, sizeof(int));
cudaMemcpy(d_match_idx, &h_match_idx, sizeof(int), cudaMemcpyHostToDevice);
The md5_compare_ctx_batched kernel is very straightforward: all it needs to do is compare the thread’s context with the target context:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
__global__ void md5_compare_ctx_batched(md5_ctx *ctxs, md5_ctx *target_ctx, int *match_idx) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < BATCH_SIZE) {
int start = idx * DIGEST_SIZE;
md5_ctx ctx = ctxs[idx];
if (ctx.a == target_ctx->a &&
ctx.b == target_ctx->b &&
ctx.c == target_ctx->c &&
ctx.d == target_ctx->d) {
*match_idx = idx;
}
}
}
We’ll also need to perform some modifications to the Rust code. We’ll replace the sequential comparison with the following code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
fn crack(digest: &str, wordlist: Vec<&str>) -> Option<String> {
let dec_digest = hex::decode(digest).expect("Failed to decode digest");
let target_digest = FfiVector::from(dec_digest);
unsafe {
let idx = md5_target_batched_wrapper(&batch, &target_digest);
if idx != -1 {
return Some(chunk[idx as usize].to_string());
}
}
...
}
That’s it! Let’s test it:
1
2
3
4
5
6
7
8
9
10
11
12
13
> Measure-Command { .\cudacracker.exe .\rockyou.txt b24aefc835df9ff09ef4dddc4f817737 }
Days : 0
Hours : 0
Minutes : 0
Seconds : 0
Milliseconds : 699
Ticks : 6993470
TotalDays : 8.09429398148148E-06
TotalHours : 0.000194263055555556
TotalMinutes : 0.0116557833333333
TotalSeconds : 0.699347
TotalMilliseconds : 699.347
Wow! We went from 56 seconds, to 39 seconds, to 13 seconds, and finally to a sub second runtime: 699ms! This is more than a 56x speedup. In the next section, we’re going to perform some benchmarks, and find out how the batch size affects the speed.
Benchmarks
Since hardware works best with powers of 2, we’ll only test batch sizes that are powers of 2. With each batch size, we’ll crack the previous MD5 hash (b24aefc835df9ff09ef4dddc4f817737), which corresponds to the password heartbreaker07. The below table shows the runtime (in ms) for cracking this hash. We use log-scale (i.e. the runtime is measured for batch size 2^x).
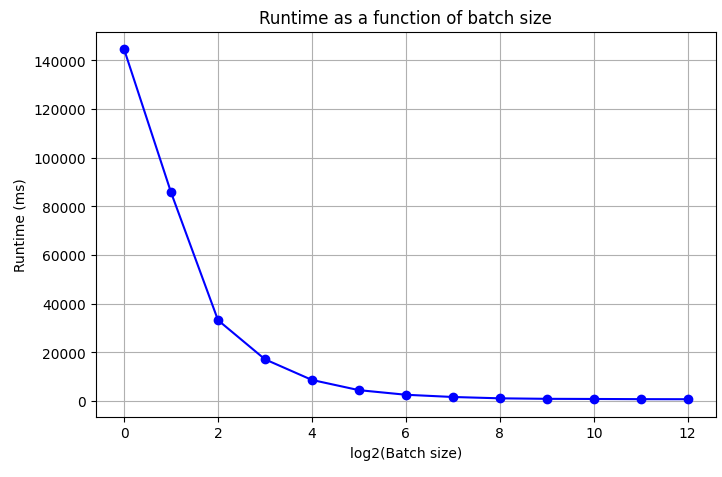 As we can see, the runtime decreases exponentially with the batch size, which is great!
As we can see, the runtime decreases exponentially with the batch size, which is great!
Conclusion
In this post, we learned about CUDA and MD5 by implementing a CUDA-accelerated hash cracker. Before writing this post, I thought that MD5 was an incredibly complicated algorithm, but implementing it didn’t turn out to be very difficult. Working with CUDA is very fun, and while I had a few annoying memory bugs, I solved them. The programming model is definitely different from usual programming, and takes a while getting used to. The optimization process was also fun, and seeing how much each change improved the performance was incredibly satisfying. In the last part of the post, we performed some benchmarks, and found that increasing the batch size improved the runtime exponentially.
Next Steps
Some things that may be interesting to do next are:
Test how the size of each block affects runtime (now we’re using a constant 32 threads per block)
Add the capability to crack multiple hashes at a time These may be covered in a future post. Hope you had as much fun reading this post as I did writing it :) The code for this post can be found here.
Yoray